数据集开源指南
这篇指南主要给大家介绍当你在社区分享自己的数据集时,我们推荐的文件格式类型,并带领大家了解如何在科赛社区更好地共享自己的数据集文件,让更多的人能够使用用你分享的数据进行有价值的分析。
数据集类型
K-Lab支持多种多样的数据集形式,科赛社区鼓励大家以公开的、平台访问友好的的数据格式来发布、分享数据,从而可以让更多的人简单、便捷地开始工作,而不用受制于工具的选择。
支持的文件格式
CSV
CSV(Comma-Separated Values,即字符分割值)是最通用的一种数据文件格式。在上传CSV文件时,应包含标题行(header row),其中每个属性字段的命名都应是可读的。举个例子,一个CSV形式的数据文件,包含用户的身高、年龄,其文件信息如下所示:
id,height,age 0,165,20 1,167,25 2,168,26 3,170,28 4,155,30
数据预览
针对CSV格式的文件,我们提供了文件内容的数据预览功能:如下图奥林匹克运动的数据集所示,在数据集的“文件”子页面上可以直观地预览CSV文件前20行的内容。
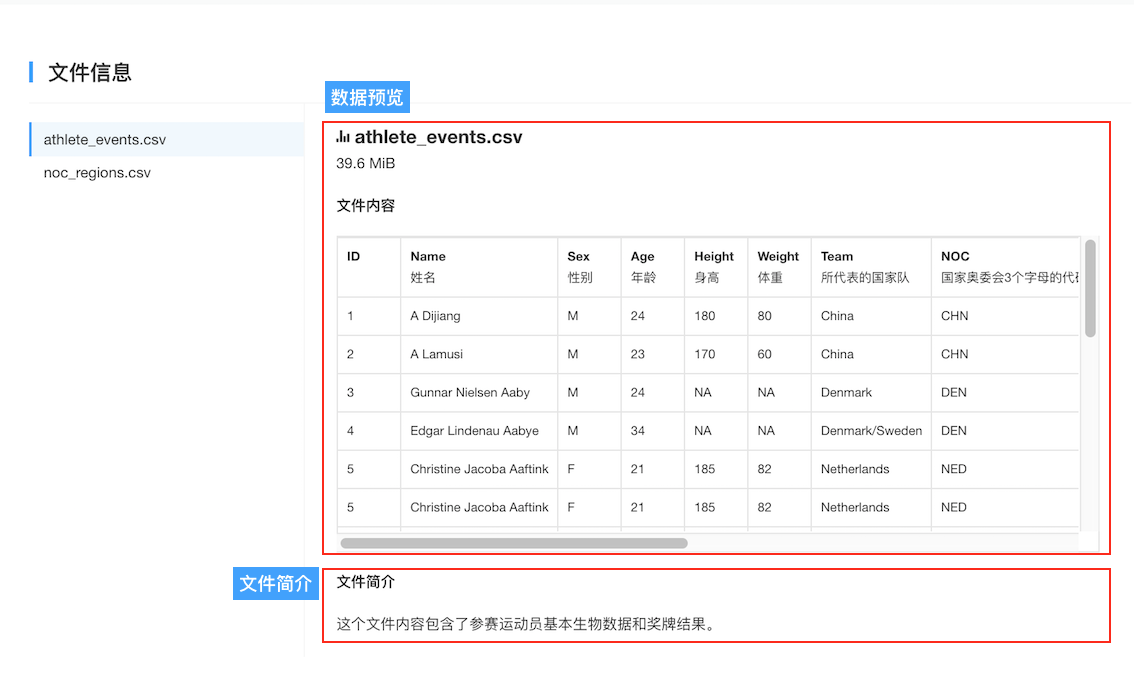
数据标注和简介
你可以点击”编辑信息“按钮,对属性字段添加标注,如:Name-姓名,Sex-性别,从而方便其他社区用户更直观地了解数据的含义。
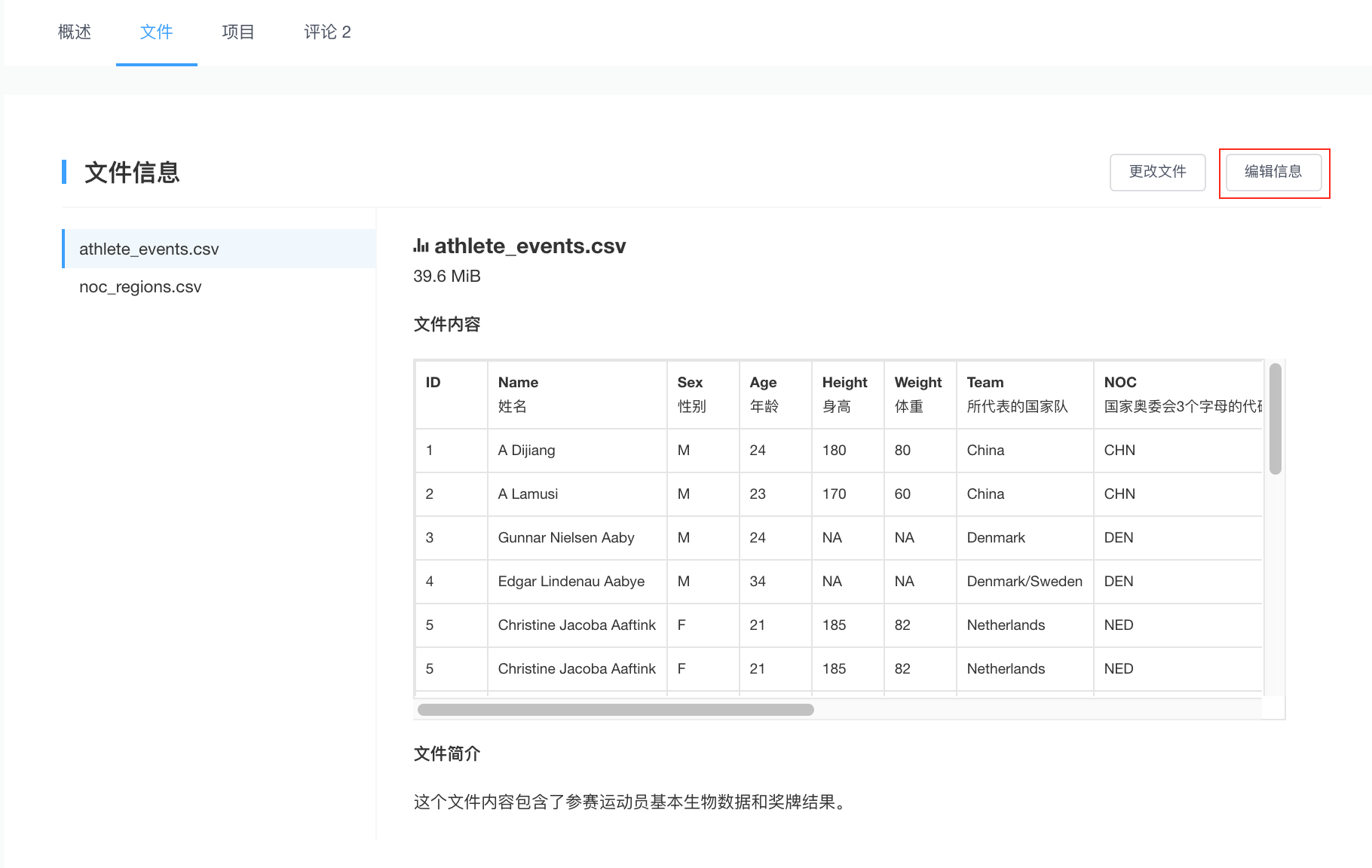
同时,对每个数据集文件你都可以添加相关的文件简介。
参考范例
数据集 120年奥运历史数据集:运动员和成绩就是一个很好的csv数据集范例。
JSON
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,也是最常见的“树状”数据(tree)的文件格式。这类格式的数据通常有多个分层,就像一棵树的分支。书写格式一般是一对“名称/值” (name/value pairs),如"name":"John"。之前提到的关于用户身高与年龄的数据用JSON格式表示的结果如下所示:
{[{'id':0, 'height': 165, 'age': 20}]}, {[{'id':1, 'height': 167, 'age': 25}]}, {[{'id':2, 'height': 168, 'age': 26}]}, {[{'id':3, 'height': 170, 'age': 28}]}, {[{'id':4, 'height': 155, 'age': 30}]}
数据预览
目前数据预览功能并不支持JSON格式,我们建议在上传了数据集的同时创建关于JSON数据读取预览的项目。
压缩文件
科赛支持如ZIP, GZ, TAR.GZ, BZ2等的压缩文件格式,且更推荐上传ZIP格式的压缩文件。
相较于未压缩的文件,压缩文件所占磁盘空间更少,且能以更快的速度上传到科赛,不用担心会超出数据集的大小限制。
如果你的数据集足够大,是由多个子文件或子文件夹组成的,或者是图片/音频数据,我们推荐你以压缩包文件的形式上传。
同时,为了让大家更好地把数据用起来,我们建议你基于上传的数据集创建一个数据预处理的范例项目,告诉大家如何进行文件解压、数据读取和数据预览,就非常棒棒了(๑•̀ㅂ•́)و✧
文件解压
在使用K-Lab挂载zip格式的数据集时,K-Lab会自动解压zip文件一级目录下的内容,二级目录及以下的zip文件则需手动解压。其他格式的压缩文件同样需要在K-Lab中手动解压缩,解压后的文件将会默认在/home/kesci/work目录下显示。你也可以在/home/kesci/目录下指定解压文件路径。但请注意/home/kesci/input目录是不能进行指令操作的。
zip文件解压
import zipfile
zip_ref = zipfile.ZipFile("/home/kesci/input/<dataset_name>/<zipfile_name>.zip", 'r')
# 方式1:默认解压至个人持久化工作区work目录下:
zip_ref.extractall()
# 方式2:自定义解压输出路径
zip_ref.extractall(output_path)
zip_ref.close()
tarfile解压
import tarfile
tar = tarfile.open("/home/kesci/input/<dataset_name>/<tarfile_name>.tar.<gz or dz2,...>")
# 方式1:默认解压至个人持久化工作区work目录下
tar.extractall()
# 方式2:自定义解压输出路径
tar.extractall(output_path)
tar.close()
其他类型文件
除了上述列举的文件格式,其他任何格式的文件都是可以上传的。比如:
- Excel电子表格文件:XLSX 、XLS;
- 文本数据文件:TXT(编码格式为UTF-8);
- 图片数据文件:PNG、JPG;
- 语音数据文件:WAV、MP3;
- 分层复杂的大量数据文件:HDF5;
- ...
由于目前K-Lab平台仅支持对于CSV文件的数据内容预览,所以如果你能将Excel电子表格文件转换成CSV文件上传,就更好啦。此外,当上传文本数据时,最好能够将字符编码格式转变成UTF-8;当上传图片时,我们更推荐使用PNG或JPG格式。同时,我们强烈建议你创建一个相应的K-Lab项目来展示这些文件的数据内容,以及如何访问、使用这些文件,并简单阐述如何进行数据集的探索。这些代码样例将有助于你的数据集被更多用户访问和推荐哦!
数据集大小限制
我们给每位用户提供了100个私有数据集和无上限的公开数据集的创建额度。每个数据集大小限制为500MB,每个数据集内的子数据文件数不能超过20个,如果所要上传的文件大小超出限制,建议进行适当拆分,或者压缩文件。
数据集创建
封面图片
为了让你的数据集更美观,更有辨识度,你可以上传与数据内容相关的图片,推荐的格式为1:1大小的PNG、JPG。你可以在pixabay和unsplash找到免费又好看的图片٩(๑>◡<๑)۶。
标题、短描述
给数据集取个简单明了的名称,配合短描述可以让大家在社区浏览时快速了解数据集的信息。
挂载目录
挂载目录就是存放数据集的文件夹名称,支持字母、数字及下划线。挂载目录设置后不可修改哦。
数据集权限
- 私有:私有数据集只有上传者自己可见,可使用,且不能分享给其他用户。
- 公开:公开数据集可以分享给其他用户,利用公开数据集创建的公开项目也可以被其他用户正常Fork、运行。公开后的数据集不能转回私有。
- 发布到社区:你可以选择将自己的公开数据集发布到社区,让更多人使用。为了不被管理员小科折叠,发布前请仔细参考数据集开源指南哦。
数据集协议
我们建议你对自己上传的公开数据集添加相应的许可协议,以便明确告知其他用户可以如何使用该数据集,科赛社区提供了一系列数据集协议供你选择,如果有特殊情况,在添加数据集协议时请选择“其他”,并在数据集文档里补充说明。数据集协议的具体说明可以参考:数据集协议
数据集文档
好的数据集都有完整的数据集文档,以便大家更快速地了解其中数据文件的内容和用途。作为数据集创建者,你可以参考我们提供的模板,完善相应的数据集文档。👇
1. 背景描述
- 关于数据集的背景、大环境、
- 数据集的主题内容,创建作者与发布时间;
- 数据集中数据所覆盖的时间段、国家范围、领域等属性特征;
2. 用K-Lab挂载数据集的方法
- Python用户,创建项目后,输入
!ls ../input/<dataset_name>/查看数据路径。 - R用户,创建项目后,输入
!list.files('../input/<dataset_name>')查看数据路径。
3. 数据说明
下面提供了3种不同类型的数据集说明的内容编辑指导,你可以根据自己的数据集类型来选择属性参考编辑。
a. 字符、数值型数据集
- 文件列表
- 数据集包含x个文件,文件格式说明;
- 列举文件名及其后缀;
- 数据集的整体特征
| 数据集名称 | 数据类型 | 特征数 | 实例数 | 缺失值 | 相关任务 |
|---|---|---|---|---|---|
| 奥运会数据集 | 字符、数值数据 | 15 | 271,116 | 有 | 可视化 |
- 属性描述 如果一个数据集中含有多个不同类型的文件数据,请依次介绍每个文件的含义及字段内容。 比如: 文件athlete_events.csv中包含15个字段,具体信息如下:
| No | 属性 | 数据类型 | 字段描述 |
|---|---|---|---|
| 1 | ID | Integer | 给每个运动员的唯一ID |
| 2 | Name | String | 运动员名字 |
| 3 | Sex | Integer | 性别 |
| 4 | Age | Float | 年龄 |
| 5 | Height | Float | 身高 |
| 6 | Weight | Float | 体重 |
| 7 | Team | String | 所代表的国家队 |
| 8 | NOC | String | 国家奥委会3个字母的代码 |
| 9 | Games | String | 年份与季节 |
| 10 | Year | Integer | 比赛年份 |
| 11 | Season | String | 比赛季节 |
| 12 | City | String | 举办城市 |
| 13 | Sport | String | 运动类别 |
| 14 | Event | String | 比赛项目 |
| 15 | Medal | Sring | 奖牌 |
文件noc_regions.csv中包含3个字段,具体信息如下:
| No | 属性 | 数据类型 | 字段描述 |
|---|---|---|---|
| 1 | NOC | String | 国家奥委会3个字母的代码 |
| 2 | Region | String | 国家 |
| 3 | Notes | String | 地区 |
b. 图片数据集
- 数据集
| 数据集名称 | 数据类型 | 实例数 | 相关任务 |
|---|---|---|---|
| CIFAR10数据集 | 图片数据 | 60,000 | 分类 |
- 数据属性
| 文件格式 | 长 | 宽 | 高 | 色彩通道 | 色彩通道数 |
|---|---|---|---|---|---|
| -- | 32 | 32 | 1 | RGB | 3 |
- 数据样本示例

c. 语音数据集
- 数据集
| 数据集名称 | 文件格式 | 实例数 | 相关任务 |
|---|---|---|---|
| 同盾声纹识别数据集 | wav | 6,000 | 声纹识别 |
4. 数据来源
请根据在创建数据集时选择的协议类型,在此处给出相对应的来源阐述。比如原数据集为CC-BY类型的,要署名数据集的作者。数据集来源链接等信息。
5. 数据集可探索、研究的方向,创建者的建议与期望
在这部分你可以描述一下能利用此数据集来解决的问题与目的。如挖掘潜在价值,构建模型进行预测,亦或是探索等。为后续用户基于该数据集的项目创建提供思路。
数据集质量
除了上述的标准之外,如果数据集包含以下特质,就更棒啦:
- 来自真实业务场景
- 缺省值少或无
- 数据格式统一
- 经过归一化处理/标准化处理
- 数据集在合理范围内容基本平衡
- 所有样本都有较高质量的正确标注
- 可以直接导入算法/模型使用
数据集的项目
为了让大家更好地把数据用起来,我们建议每个数据集的上传者都能基于自己上传的数据集创建一个数据预处理的范例项目,告诉大家如何进行文件解压、数据读取和数据预览。
一个完整的Notebook项目应包含以下模块:
- 数据预处理
- 建模过程
- 结果分析
- 在每个模块和代码之间需要必要的文字说明,你可以参考我们的Notebook推荐模板